Google Dialogflow CX and Deepgram
Dialogflow CX is a framework for building virtual agents. Learn how to incorporate Deepgram’s transcription and text-to-speech for improved accuracy.
In this guide, we’ll explain how to talk to a Dialogflow CX agent using Deepgram for transcription and text-to-speech. We’ll do this by walking through Deepgram’s Dialogflow Example repo on GitHub.
Before you Begin
Before you can use Deepgram, you’ll need to create a Deepgram account. Signup is free and includes $200 in free credit and access to all of Deepgram’s features!
Before you start, you’ll need to follow the steps in the Make Your First API Request guide to obtain a Deepgram API key, and configure your environment if you are choosing to use a Deepgram SDK.
Create a Dialogflow CX Agent
You’ll also need a Dialogflow agent to talk to. If you don’t already have one, the easiest approach is to create a prebuilt agent.
Try Out the Demo
Clone the Dialogflow Example repo and follow the instructions in README.md. You’ll need to provide your Deepgram API key and your Dialogflow agent information. The video in the README shows how the demo should work.
High-Level Architecture
Dialogflow agents can accept user input in the form of audio or text. If you send audio to an agent, Google will transcribe it with their own speech-to-text engine. In order to use Deepgram’s transcription, we need to transcribe the audio outside of Dialogflow and send the resulting text to our agent. If we also want to use Deepgram’s text-to-speech for the bot’s voice, we must configure Dialogflow to return agent responses as text. This diagram depicts the full process:
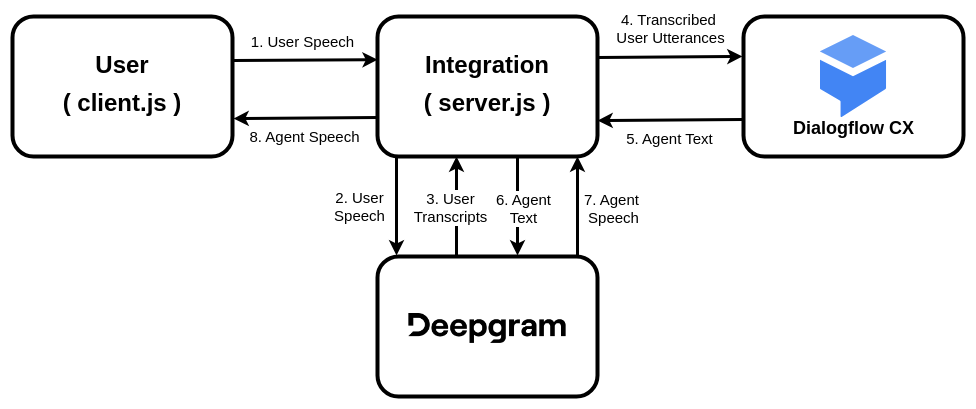
- The user speaks into their microphone.
- The integration continuously streams the user’s speech to Deepgram.
- Deepgram streams back transcripts.
- The integration analyzes the transcripts to determine when the user has completed a thought (“utterance segmentation”). When it finds a complete utterance, it sends it to the Dialogflow agent as text.
- The agent replies with its response, also in the form of text.
- The agent’s response is sent to Deepgram’s text-to-speech engine.
- Deepgram returns the response as audio.
- The audio is played to the user.
- The process repeats until the conversation is finished.
Deeper Look
At any given time, server.js is in one of two states. In the awaiting utterance state, it is collecting transcripts from Deepgram and looking for an indication that the user has finished their thought. In the awaiting bot reply state, it is discarding transcripts because we’ve already sent the utterance to Dialogflow and it is now the bot’s turn to speak.
This is the code that runs when server.js receives a transcription result from Deepgram (note the two states):
finalizedTranscript is all of the concatenated is_final=true results that we’ve received since the start of the current utterance. unfinalizedTranscript is the most recent is_final=false result for which we have not yet seen an is_final=true. (If these concepts are unfamiliar, have a look at the documentation on interim results.)
When we detect that the current finalizedTranscript contains a full utterance, we send it off to Dialogflow and await the agent’s reply.
This detection happens when there is a sufficient period of silence after the transcript. That is, when either of these conditions is met:
- We’ve reached an endpoint (
speech_final=true), or - The transcripts reveal a 1.25 second silence after the last finalized word.
Options for Customizing Utterance Segmentation
The approach described above is a solid starting point for detecting end of utterance, but depending on your needs you may want to explore various customizations. For example, you can adjust the endpointing and silence detection values (currently set to 500ms and 1.25s, respectively). Below are some additional modifications you might consider.
Update Dialogflow with Resumed Utterances
You may want to send tentative utterances to Dialogflow. Then if the user resumes speaking before the agent has replied, you can cancel the original Dialogflow operation and send the new, full utterance to Dialogflow instead. This comes with a couple of advantages:
- Lower latency. For example, you can set endpointing to a snappy
10msand send the utterance to Dialogflow right away at an endpoint. Then you get the agent reply and hold it until you verify that the user has really stopped speaking, at which point you send it to the user immediately. - Last-minute interjections. With this approach the user is able to add to their utterance right until the bot reply is sent to them.
If you go this route, make sure that any actions taken by the Dialogflow agent on the tentative utterance are indeed reversible in the event of a replacement utterance. It is possible to rewind the state of the agent itself (see the parameters here), but the agent can’t uncall any webhooks that it called while fulfilling the user’s request.
Don’t Segment on Endpoints
Endpointing is sometimes said to be a poor indicator of end of utterance. On one hand, an endpointing value that is too low can lead to false positives. On the other hand, an endpointing value that is too high may simply not fire due to background noise. So you can try leaving endpointing at its default value of 10ms (for rapid finalization of transcripts) and only doing utterance segmentation based on word timing analysis.
Replace Word Timing Logic with utterance_end_ms
Finally, you may choose to use Deepgram’s UtteranceEnd feature in place of the word timing logic. This is really a matter of preference; do you prefer the conciseness of the built-in UtteranceEnd message, or the clarity and flexibility of the explicit word timing logic?
AudioCodes as an Alternative
Deepgram’s partner AudioCodes offers a managed solution called VoiceAI Connect, which enables you to pair Deepgram’s speech-to-text with many different bot frameworks, including Dialogflow CX. Read more about our integration with AudioCodes here.
What’s Next